
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- aws
- 패키지설치에러
- 호스팅영역
- 웹소켓연결
- javascript
- nodejs
- 버킷생성
- gitlab
- java
- 웹소켓재시작
- class
- 노드버전
- db
- ChatGPT
- gptapi
- nvmrc
- Database
- aiapi
- 웹소켓연결끊김
- 클라우드
- 클래스
- chatGPTAPI
- gpt3.5turbo
- Github
- 자바
- Express
- git
- GPT3.5
- openaiapi
- iam사용자
- Today
- Total
IT's Jenna
1. SQL과 관계형 모델 본문
SQL이란?
관계형 모델이란?
SQL과 관계형 모델의 비교
1. SQL이란?
SQL이란, Structured Query Language의 약자로 구조적 질의 언어를 뜻한다. 관계형 데이터 베이스(RDB)에 질의를 하기 위한 언어이다.
2. 관계형 모델이란?
관계형 모델을 알기 위해서 우선 데이터 모델의 정의를 알아보자. 데이터 모델은 "데이터를 어떻게 표현할까?"를 의미한다. 어떤 개념을 사용해서 데이터를 어떤식으로 표현할 것인가! 그것이 데이터 모델이고 그렇게 데이터를 표현하는 여러 가지 개념들 중에 하나가 바로 관계형 모델이다.
관계형 모델을 이해하는데 중요한 개념이 바로 릴레이션(Relation)이다. 릴레이션은 관계형 모델에서 데이터를 표현하는 방식이고 구성은 다음과 같다.

- Relation은 제목(Head)과 본체(Body)로 구성되어 있다.
- 제목은 속성(attribute)이 n개 모여있는 집합이다. 속성은 해당 속성명과 데이터 타입 2가지로 구성되어 있다.
- 본체는 속성 값의 집합이다. 본체의 속성 값 하나하나를 튜플(Tuple)이라고 한다.
- 즉, 릴레이션이란 제목과 본체의 쌍을 가진 관계이다.
3. SQL과 관계형 모델의 비교
관계형 모델과 SQL을 비교해보면 다음과 같다.
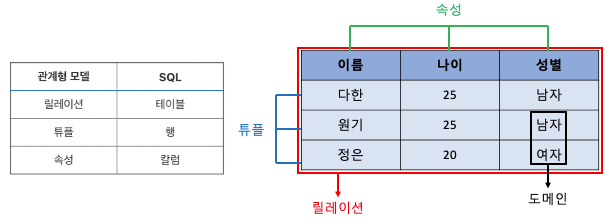
- 위 그림의 전체 테이블이 바로 릴레이션이다.
- 이름/나이/성별로 구분되어 있는 열(Column)이 속성이다.
- 해당 속성의 값들인 각각의 행(Row)들이 튜플이다. ex) 홍길동/18/남자
- 도메인이란 속성들이 가질 수 있는 값들의 범위가 지정되어 있는 집합이다. 예를 들어 성별이라는 속성이 있으면 해당 속성이 가질 수 있는 값은 남자 또는 여자뿐이다. 그렇다면 SEX라는 도메인을 만들어서 해당 도메인에 남자, 여자만 넣어둔다. 그리고 성별 속성의 도메인으로 SEX를 지정해두면 사용자는 해당 도메인에 있는 값 외에 다른 값을 선택할 수 없다.
관계형 모델에서 데이터를 어떻게 표현하는지 알아보았다. 데이터는 그 자체로는 아무런 의미를 가지지 못한다. 해당 데이터가 어떻게 연산되어서 어떤 결과를 출력하느냐! 그것이 포인트이다. 여기서 데이터는 릴레이션이고, 연산은 쿼리이다.
즉, 관계형 모델이란 릴레이션 단위로 다양한 연산을 사용해서 질의를 수행하는 데이터 모델이다.
그렇다면 릴레이션에 사용할 수 있는 다양한 연산을 알아보도록 하자. 릴레이션은 기본적으로 집합을 바탕으로 이루어져 있다. 따라서 집합에서 사용되는 연산을 적용 가능하다.
1. 제한(Restrict)과 프로젝션(Projection)


- 제한은 특정 조건에 해당하는 튜플을 포함한 릴레이션을 반환하는 것이다.
- 프로젝션은 튜플에 조건을 거는 것이 아니라 특정 속성 값만 반환하도록 한다.
2. 확장(Extend), 속성명 변경(Rename)

- 확장은 속성 값을 추가한다. 일반적으로 기존의 속성 값을 이용해서 계산한 값으로 새로운 속성 값을 만든다.
- 속성명 변경은 말 그대로 속성의 이름을 변경한다. 주로 확장한 속성에 명칭을 부여할 때 사용된다.
3. 합집합, 교집합, 차집합, 곱집합
아래와 집합 연산의 예시를 보자.




- 합집합은 두 릴레이션을 모두 합친 튜플을 나타낸다. 두 테이블에 동일한 데이터가 있는 경우 중복 값이 제거된 상태가 된다.
- 교집합은 두 릴레이션이 모두 포함하고 있는 공통부분만 반환한다.
- 차집합은 두 릴레이션 중 하나의 릴레이션에만 포함하고 있는 값을 반환한다. 어떤 릴레이션을 기준으로 계산하느냐에 따라 결과값이 달라진다.
- 곱집합은 두 릴레이션에 있는 튜플을 조합하여 반환한다. 예를 들어 각 릴레이션의 튜플이 5개 3개인 경우, 15개의 튜플 값이 반환된다.
4. 결합(Join)

- 조인은 공통된 속성을 가진 두 릴레이션에서 공통된 속성 값이 같은 튜플끼리 조합한 값을 반환한다. 해당 조인은 SQL에서는 이너조인(Inner Join)이라고 한다.
이렇게 다양한 연산을 사용해서 데이터를 출력할 때 유념해야 하는 개념이 클로저(Closure)이다. 클로저란 연산의 입력과 출력이 같은 데이터 구조를 가져야 한다는 성질이다. 즉, 릴레이션 데이터를 입력받아서 연산하면 다시 릴레이션 데이터를 출력해야 한다는 의미이다. 입력과 출력 구조가 일치해야 연속적인 연산이 가능해지고, 연속적인 연산이 가능해야 더욱 복잡한 연산 구조를 만들 수 있다.
지금까지 데이터 모델에서 릴레이션을 어떻게 연산하는지 알아보았다. 그렇다면 SQL에서 해당 릴레이션을 어떻게 조작하는지 알아보자.
SQL에서 기본적인 CRUD를 실행하는 연산이 있다. 바로 SELECT, INSERT, DELETE, UPDATE이다.
1. SELECT
SELECT문은 SQL에서 데이터를 조회하는데 사용하는 유일한 명령이다. 따라서 모든 질의는 SELECT문 안에서 동작하고 그만큼 SELECT문을 어떻게 활용하느냐가 RDB의 핵심이라고 볼 수 있다. 아래는 SELECT문의 기본형이다.
SELECT 칼럼의 목록
FROM 테이블의 목록
WHERE 검색 조건- 해당 연산을 릴레이션 연산과 비교해보면, 칼럼의 목록은 프로젝션, 테이블의 목록은 곱집합, 검색 조건은 제한 연산이다.
- 릴레이션 연산의 순서 : 테이블 목록(곱집합) -> 검색 조건(제한) -> 칼럼의 목록(프로젝션) 순으로 진행된다.
2. INSERT
INSERT문은 SQL 테이블의 하나의 행을 추가하는 것이다. 아래는 INSERT문의 기본형이다.
INSERT INTO 테이블 (속성1, 속성2, 속성3) VALUES (1, 2, 3)- 해당 연산은 릴레이션 연산의 합집합이다.
- 클로저 성질에 따라 입력과 출력이 모두 릴레이션이 되어야 하므로 기존 릴레이션에 하나의 튜플 값만 가지고 있는 릴레이션을 합쳐서 새로운 릴레이션을 생성하고 대입한다.
- R := R U {T}
3. DELETE
DELETE문은 SQL 테이블의 하나의 행을 삭제하는 것이다. 아래는 DELETE문의 기본형이다.
DELETE FROM 테이블 WHERE 속성1 = 10
- 해당 연산은 릴레이션 연산의 차집합이다.
- 기존 릴레이션에 하나의 튜플 값만 가지고 있는 릴레이션을 빼서 새로운 릴레이션을 생성하고 대입한다.
- R := R - {T}
4. UPDATE
UPDATE문은 SQL 테이블의 특정 튜플을 수정하는 것이다. 아래는 UPDATE문의 기본형이다.
UPDATE 테이블 SET 속성1 = 1 WHERE 속성2 = 10- 해당 연산을 릴레이션 연산과 비교해보면 다음과 같다.
- WHERE 조건에 해당하는 릴레이션의 차집합을 구하고 반환된 릴레이션을 수정한다.
- 수정된 릴레이션과 처음 연산된 릴레이션의 합집합을 구한 후 대입한다.
- WHERE절 조건에 해당하는 릴레이션 T1, T1을 수정한 릴레이션 T2
- R := {R - {T1}} U {T2}
이번장에서는 SQL이 무엇인지 그리고 관계형 데이터 모델이 무엇인지에 대해서 알아보았다. SQL의 연산은 기본적으로 관계형 모델을 바탕으로 이루어지고 있다. 따라서 SQL을 더욱 잘 활용하고 데이터 베이스를 적절하게 설계하기 위해서는 관계형 모델을 이해하는 것이 중요하다. 다음장에서는 관계형 모델을 더 자세히 이론적인 관점에서 알아보도록 하겠다.
'Study > 관계형 데이터 베이스 실전 입문' 카테고리의 다른 글
| 7. NULL과의 싸움 (0) | 2021.06.01 |
|---|---|
| 6. 도메인 설계 전략 (0) | 2021.05.28 |
| 5. 릴레이션의 직교성 (0) | 2021.05.27 |
| 4. 정규화 이론(두 번째) - 결합 종속성 (0) | 2021.05.26 |
| 3. 정규화 논리(첫 번째) - 함수 종속성 (0) | 2021.05.21 |



